AI AGENT 변곡점에서의 병목
2026년 7월 8일 업데이트
이삭 · 불스토리 크리에이터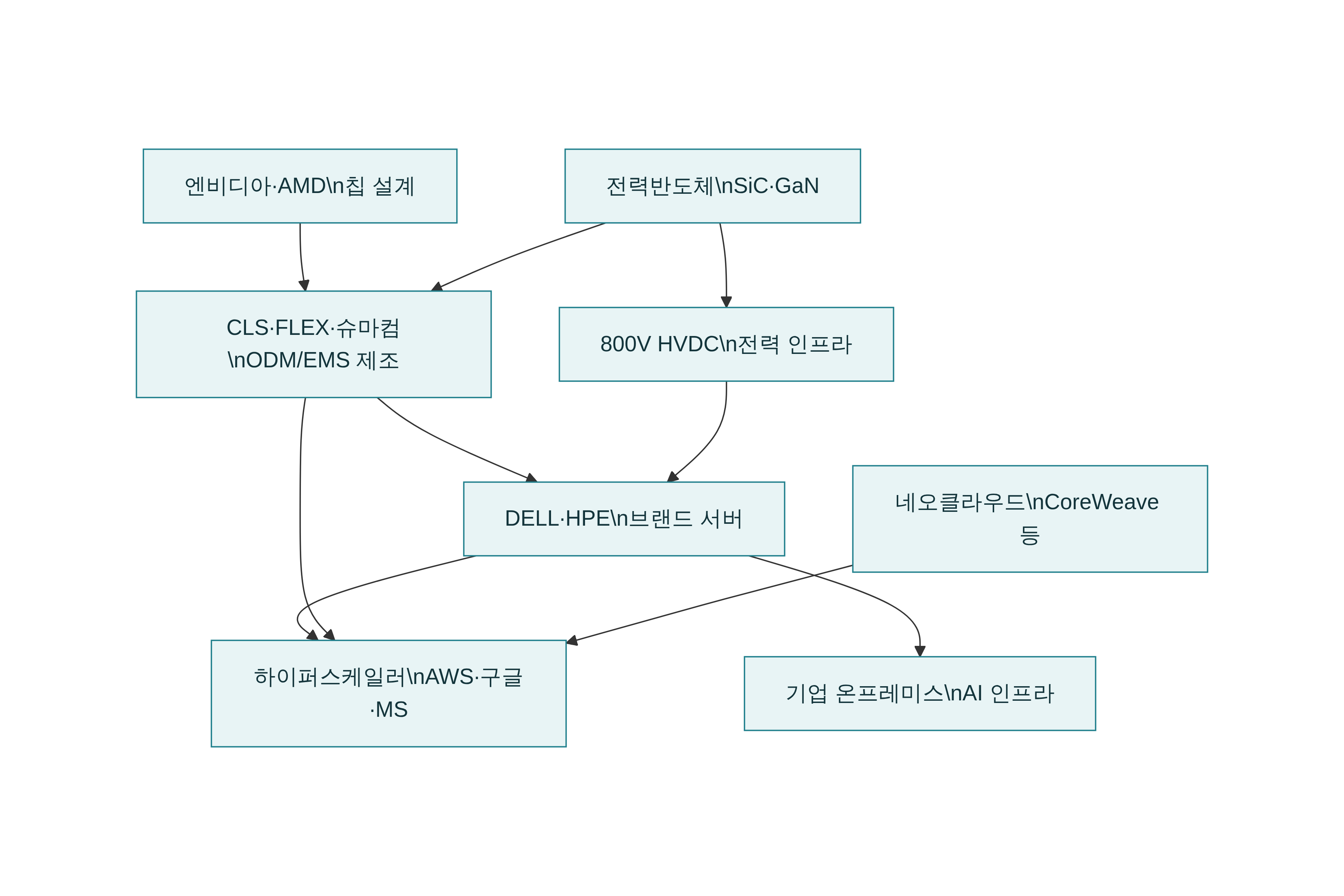
KV CACHE가 메모리 병목을 만들고, 2026년 HBF 상용화가 해결 분기점이다. HBF는 HBM 용량을 8~16배로 늘려 NAND 수요를 급증시킨다. SK 하이닉스가 표준화 주도.
AI 추론 전환은 NAND·SSD를 단순 보조기억장치에서 AI 인프라의 핵심 자원으로 바꿨다. AI 서버 한 대에 필요한 스토리지는 기존 서버의 8~10배로 늘어나 KV CACHE 등 대용량·실시간 접근을 위한 엔터프라이즈 SSD 수요가 급증한다. NAND 수요는 연간 20~22% 증가하는데 설비 전환은 더뎌 공급 압박이 이어진다.
1. AGENT AI 의 등장
AGENT AI는 목표를 주면 스스로 계획을 세우고 도구를 고르고 실행하며 결과를 평가하는 AI다.
기존 LLM 은 챗봇에 불과했다. 사람을 대신하기 보다는 서포트 역할에 가까웠다.
그러나 AGENT AI 는 직접 컴퓨터에 들어와 사람처럼 작업을 하고 업무를 한다.
그리고 LLM 과는 달리 돈이 된다. 경쟁에서 살아남아 수익화를 위해 AI 기업들은 AGENT AI 모델에 사활을 걸고있다.
AI 버블은 이제 초입단계다. CAPEX 투자를 줄일수는 없다. 매몰비용이 생기기 때문이다.
AGENT AI 는 LLM 보다 일을 훨씬 많이 해서 수많은 병목이 생긴다.
전력 (SOFC, 가스터빈) / CPU, GPU, TPU, NPU, HBM / 메모리 DRAM, NAND, HDD / 기판 , 구리*광통신 등 인터커넥트
/전력반도체 , AI PC / 데이터센터 건설, 네오클라우드 / 까지 수없이 병목이 발생하고 있다.
2. 왜 지금 AGENT AI 인가?
기존 AI 는 질문하면 답하는 일회성 챗봇이고, 사람이 매번 지시해야 한다.
AGENT AI 는 목표 → 계획 → 실행 → 피드백 → 반복으로 스스로 판단하고 행동한다.
AGENT AI 는 24 시간 자동화된 디지털 노동자로, 반복 업무 제거, 인건비 절감, 매출 기회 증가로 직접적인 수익 창출을 한다.
기업 수요 폭발 "실제 비용 절감, 매출 증가"
-
반복 업무 자동화: 지원, 영업, 재무, 프로덕트 등 전 분야에서 AI 직원 수요
-
24 시간 AI 직원: 사람이 없는 시간에도 업무 진행 → 매출 기회 증가
-
실제 비용 절감: 도입 기업 중 83%가 반복 업무 제거, 76%가 생산성 향상 경험
수익 영향: 도입 비용 < 절감된 인건비 + 늘어난 매출 → ROI(투자수익률) 명확
3. 메모리(DRAM·NAND)의 병목
KV CACHE: 메모리 병목의 핵심 원인
KV CACHE(Key-Value Cache) 는 AGENT AI 추론 과정에서 메모리 병목을 만드는 핵심 원인이다.
KV CACHE란? AI 가 문장을 생성할 때, 이전에 계산한 Key 와 Value 값을 메모리에 저장해 다시 계산하지 않고 바로 쓰는 기술.
문제: AGENT AI 는 수백만 토큰을 실시간 처리해야 하는데, KV CACHE 용량이 메모리 한계를 초과하면 GPU 가 그냥 기다려야 한다. 이것이 "메모리 병목 (Memory Wall)" 이다.
결과: GPU 연산 속도는 폭발적으로 늘었지만, 메모리가 그 속도로 데이터를 못 공급하면 고가의 GPU 가 낭비된다.
NAND 중요성이 급부상한 배경
DRAM 기반 HBM 만으로는 용량 한계(192GB)와 비용 부담이 크다.
NAND(낸드 플래시) 가 중요해진 이유:
-
용량: DRAM 대비 10 배 더 큰 저장 공간
-
비용: HBM 대비 8~16 배 저렴
-
비휘발성: 전원 끊어도 데이터 유지
키 포인트: AI 추론 시대에서 KV CACHE 를 담을 대용량 저비용 메모리가 필수 → NAND 수요 폭발.
AI 추론 전환이 NAND·SSD 시장을 바꾼 구조 (2024~2026)
OpenAI의 o1 공개(2024년 9월)를 기점으로 AI 기술 중심이 학습에서 추론으로 이동했다. 이 한 번의 구조적 이동이 저장장치 수요 지도를 바꿨다.
추론 단계에서는 모델이 요청마다 대규모 데이터를 빠르게 불러온다. KV 캐시와 벡터 데이터베이스 접근이 상시로 일어나면서, 고속·고용량의 엔터프라이즈 SSD 수요가 GPU 수요와 함께 급증했다(TrendForce, 2026년 5월).
다음은 눈에 보이는 변화다. 2026년 AI 서버 한 대에 필요한 스토리지는 기존 서버의 8~10배다. NAND 수요는 연간 20~22% 늘어나는데 공급은 15~17% 수준에 그친다(Commercial Times, oscoo 분석, 2026년). 수요는 빠른데, 생산·설비 전환은 그 속도를 못 따라간다.
NAND 공급이 줄어드는 역설
수요가 급증하는데도 공급이 못 따라가는 이유는 업계의 설비 배치 때문이다. 삼성과 SK하이닉스가 NAND 라인을 HBM 쪽으로 전환하고 있다. HBM 마진이 60%를 넘기기 때문이다. 삼성 웨이퍼 생산량은 2025년 490만 장 → 2026년 470만 장으로 줄었다는 보고도 있다. NAND 설비투자는 전년 대비 5% 증가에 그쳤다. 마이크론은 신규 공장이 2027년 이전에는 가동이 어렵다고 했다. SK하이닉스는 2025년 10월 실적 발표에서 2026년 물량이 이미 완판됐다고 밝혔다(oscoo, storageswiss.com, 2026년).
이런 구조적 이동은 단기 공급 부족을 심화시킨다. 수요는 데이터센터·추론 중심으로 재편되는데, 공급은 고이윤 HBM 생산으로 돌아가 있다. 결과적으로 엔터프라이즈 SSD 쪽 가격과 재고 압박이 커진다.
SSD 가격과 시장 변화 — 지금 일어나는 일
가격은 이미 반응했다. TLC 1테라비트 NAND 단가는 2025년 중반 4.80달러에서 2025년 말 10.70달러로, 6개월 만에 두 배가 됐다는 발언이 나왔다(Phison CEO, Tweaktown, 2025년 11월).
소비자용 1TB SSD 가격도 올랐다. 2025년 초 45~60달러였던 제품이 2025년 9월 이후 70~90달러 이상으로 상승했다. 산디스크는 2026년 초 WD Black SN8100 4TB 모델 가격을 549.99달러 → 1,289.99달러로 올린 사례를 공개했다(Kingspec 분석, kitpa.org, 2026년 2월).
마이크론은 2025년 12월에 소비자 브랜드인 Crucial 사업을 접기로 결정했다. 2026년 2월부터 소비자용 신제품 출하를 중단하고 생산 전량을 AI·엔터프라이즈 용도로 돌렸다(oscoo, 2026년).
엔터프라이즈 SSD가 모바일을 추월하는 역사적 전환
2026년은 데이터센터가 처음으로 모바일을 제치고 NAND 최대 수요처가 되는 해가 될 가능성이 크다. 산디스크 CEO는 2026년 1월 실적 발표에서 데이터센터 NAND 용량 성장률을 "연간 60%대 후반"으로 제시했다. 마이크론의 2026 회계연도 NAND 매출은 전년 대비 178% 증가한 약 236억 달러로 월가에서 추산된다(산디스크 실적 발표, Zacks, 2026년).
TrendForce는 2026년 글로벌 NAND 플래시 시장 규모 전망치를 2,706억 달러로 상향 조정했다. 전년 대비 281% 성장이라는 수치다. 2027년은 3,794억 달러로 추가 확대 전망을 제시했다. 다만 실질적 공급 확대는 2027년 말~2028년 이전에는 어려울 것이라는 업계 시각도 있다(TrendForce, 2026년 5월).
결론적 관점: AI 추론이 스토리지 수요의 중심이 되면서, NAND·SSD는 단순한 보조기억장치에서 AI 인프라 핵심 자원으로 탈바꿈했다. 수요 폭증에 비해 설비 전환은 느리다. 이 때문에 엔터프라이즈 SSD와 대용량 NAND가 메모리·스토리지 분야에서 단기적·구조적 투자 포인트가 됐다.
HBF 기술: HBM 의 용량 한계를 8~16 배 돌파
HBF(High Bandwidth Flash, 고대역폭 플래시) 는 HBM 을 대체하는 게 아니라 HBM 의 용량 한계를 보완하는 차세대 메모리다.
HBF 핵심 설명
-
소재: NAND 플래시(DRAM 기반 HBM 과 다름)
-
용량: HBM 대비 8~16 배更大 (GPU 당 최대 4TB 가능)
-
속도: HBM 의 80~90% 수준 (충분히 빠름)
-
비용: 유사 비용으로 8~16 배 용량
-
역할: HBM은 캐시(빠른 데이터 처리), HBF는 도서관(대용량 AI 모델 저장)
HBF 기술 구조
-
3D 스택형 낸드: 여러 NAND 다이 세로로 쌓아 하나의 패키지화
-
TSV(실리콘 관통 전극): 각 낸드 다이를 수직 연결, 대역폭 확대
-
CBA(웨이퍼 본딩): 메모리셀과 회로 직접 결합, 성능 향상
-
다중 서브어레이: 동시 액세스로 읽기 대역폭 극대화
상용화
-
2026 년 하반기: HBF 메모리 첫 샘플 제공
-
2027 년 초: HBF 탑재 AI 추론 장치 첫 샘플
💡관련 기업
키 포인트: 2026 년 HBF 상용화, 메모리 시장 수익성 급증의 핵심 변수.
HDD 수요 폭발: 대용량 보관의 필수
HDD(하드 디스크) 는 SSD 대비 5~8 배 저렴하고 대용량 보관에 최적이다.
HDD 수요 폭발 배경
-
AI 데이터량 3 배 급증(2023~2028, 400 제타바이트)
-
약 80% 는 비용 효율성 때문에 HDD 에 담김
-
학습·추론 데이터 아카이브: 저장 필요 → HDD 가성비 우수
최근 HDD 시장 동향
-
HDD 가격: 공급가 4% 상승, 실제 판매가 20% 상승
-
HDD 납기일: 최대 1 년 이상 늘어 (품귀 현상)
-
2026 년: 출하량 반등
-
2028 년: 출하량 2 억 대 돌파, 단일 최대 용량 60TB 도달
💡관련 기업
-
웨스턴디지털: HDD 세계 1 위, 전 제품 가격 즉시 인상
-
씨게이트: HDD 2 위, 가격 인상 계획 발표
결론
KV CACHE 는 메모리 병목의 핵심 원인이고, HBF 는 HBM 의 용량 한계를 8~16 배 돌파하는 차세대 AI 메모리다.
NAND 는 대용량·저비용으로 중요성이 급부상하고, HDD 는 대용량 보관에 필수다. (SSD 가격이 오르니 HDD도 수혜)
2026 년 HBF 상용화가 메모리 시장 수익성 급증의 핵심 변수. SK 하이닉스·삼성전자·SanDisk가 주도.
4. 네트워킹의 병목
AGENT AI는 혼자 일하지 않는다. 수천 개의 GPU 가 팀으로 협력해 하나의 대형 모델을 학습하거나 추론한다.
문제: GPU 연산 속도는 폭발적으로 늘었는데, GPU 사이를 연결하는 네트워크 속도가 그 뒤를 못 따라가는 현상.
결과: GPU 가 데이터를 기다리는 시간이 늘어나 고가의 GPU 가 낭비된다. 이것이 "네트워킹 병목" 이다.
GPU 연결 속도가 GPU 연산 속도를 따라가지 못하면, AI 인프라 전체가 막힌다.
💡 관련 기업
-
CRDO : AI 가속기 간 초고속 연결 칩핵심: GPU 간 데이터 전송을 위한 인터페이스 칩 전, PAM4 고속 트랜스시버
-
ALAB : 광통신을 칩과 통합하는 CPO 칩, GPU 간 광통신 연결 솔루션핵심: CPO 기술 선점, 칩 + 광모듈 통합 선도
-
ANET : AI 데이터센터용 400G/800G 스위치, 고대역폭 이더넷 스위치핵심: CLS 의 주요 고객사, AI 데이터센터 네트워킹 선도
-
CLS : 고대역폭 스위치, 화이트박스 스위치, AI 서버 랙·네트워크 스위치 제조 핵심 (CPO 기반 스위치 제조)
광통신 주목 배경
광통신(Optical Communication) 은 빛을 이용해 데이터를 전송하는 기술로, 전선 대비 속도가 훨씬 빠르고 전력 소모가 적다.
광통신이 주목받는 이유:
-
고속: 초당 수 테라비트(Tbps) 전송 가능
-
저전력: 전선 대비 50% 전력 절감
-
저지연: 신호 지연 최소화
-
대용량: AI 데이터센터의 거대 데이터 전송 필수
키 포인트: AI 데이터센터에서 수천 GPU 를 연결하려면 광통신이 필수다.
MRVL 의 성장
3월 엔비디아 계약 후 매우 가파르게 성장, 엔비디아 생태계에 들어가며 최근 젠슨황 1조 기업 발언
-
AI 서버 간 데이터 전송량 폭발 → 800G·1.6T Ethernet 스위치 수요 급증
-
AI 랙 간 광통신 필요 → 마벨 광트랜시버 핵심 공급
-
브로드컴 (Broadcom) 과 함께 이더넷 스위치 2 대장
-
마벨은 AI 데이터센터 네트워크의 핵심, 기판 병목 구조에서 네트워크·광통신 병목을 대표하는 기업
CPO 기술: 네트워킹 병목 해결의 핵심
CPO(Co-Packaged Optics, 공동 패키지 광학) 는 광통신 소자를 칩과 한 패키지에 붙여서 데이터 전송 지연과 전력 소모를 동시에 줄이는 기술이다.
전통 방식:
-
광통신 모듈이 칩과 분리
-
데이터가 전선을 타고 모듈까지 이동 → 전력 손실, 지연 발생
CPO 방식:
-
광통신 모듈이 칩과 한 패키지 (물리적으로 통합)
-
데이터가 바로 연결 → 전력 50% 절감, 지연 최소화
CPO 기술 진행 상태
| 항목 | 내용 |
|---|---|
| 대역폭 | 기존 400G → 1.6T 이상 |
| 전력 | 50% 절감 |
| 상용화 | 2026 년 본격 도입 |
| 시장 | 2028 년 100 억 달러 이상 |
💡관련 기업
-
LITE : 광트랜스시버, 레이저, 검출기 등 광통신 핵심 부품핵심: 광통신 모듈 공급, CPO 대응 광소자 생산
-
COHR : 고성능 광트랜스시버: 800G/1.6T 광통신 모듈 , 광통신용 레이저핵심 (고대역폭 광소자, CPO 광모듈 공급)
-
AAOI : 400G/800G 광트랜스시버: AI 데이터센터용, 고속 이더넷 솔루션핵심: 광통신 모듈 공급, AI 서버 네트워킹
-
MXL : PPM: 광통신 신호 처리 칩, 네트워킹용 아날로그 부품핵심: 광통신 신호 처리, 네트워킹 칩
-
TSEM : 반도체 패키징·칩 통합, 웨이퍼 본딩 기술, 3D IC 패키징: 칩을 수직으로 적층하는 기술
-
VIAV : 광통신 네트워크 테스트·측정, CPO 테스트 장비
-
POET : 광 인터포저, Optical I/O: AI 가속기 간 광통신 연결핵심 (CPO 기술 선점, 칩 + 광모듈 통합)
-
KEYS : 통신 측정 장비: 광트랜스시버 성능 검증, 고속 인터페이스 테스트: 112G PAM4 체크
-
GLW : 광섬유(Optical Fiber): 데이터센터 간 초고속 연결 , 유리 기판(Glass Substrate): CPO 기반 칩 통합
광소자 소재: 레이저, 검출기 등 광통신 부품핵심 (광통신 소재, CPO 유리 기판 공급)
5. CPU의 병목
AGENT AI 시대의 CPU 병목은 “GPU만 빠르다고 끝나는 문제가 아니다”로 정리된다. 에이전트형 워크로드는 추론 자체보다도 오케스트레이션, 메모리 관리, 데이터 전처리, 툴 실행, 스케줄링 같은 CPU 성격의 작업이 늘어나서 CPU 중요도가 다시 커졌다.
초기 생성형 AI는 “GPU가 전부”처럼 보였지만, AGENT AI로 오면서 CPU가 맡는 일이 급증했다. AI 에이전트는 모델 호출만 하는 것이 아니라 여러 단계의 작업을 조율하고, 외부 도구를 호출하고, 데이터를 옮기고, 결과를 다시 연결해야 해서 CPU가 시스템의 교통정리 역할을 훨씬 많이 하게 됐다.
핵심은 CPU가 느리면 GPU가 놀게 된다는 점이다. 엔비디아도 Vera CPU를 소개하면서 에이전틱 AI, 강화학습, 데이터 처리, 오케스트레이션이 CPU 집약적 작업이라고 설명했고, Vera가 x86 CPU 대비 에이전트 작업 완료 속도를 80% 높인다고 밝혔다
왜 지금 변곡점인가
시장은 이미 CPU 수요 구조가 바뀌고 있다고 본다. 일부 업계 분석에서는 전통적인 LLM 배치에서 CPU 비중이 서버 수요의 약 15% 수준이었지만, AGENT AI가 확산되면 그 비중이 50% 수준까지 커질 수 있다고 봤다.
이 변화는 단순한 성능 경쟁이 아니라 아키텍처 전환도 같이 부른다. Arm은 데이터센터 CPU 매출 기준 점유율이 2025년에 50%까지 뛸 수 있다고 밝혔고, AI ASIC 서버용 호스트 CPU 시장에서는 2029년 초 Arm 기반 CPU가 90%를 차지할 수 있다는 전망도 나왔다.
💡관련 기업
-
AMD : AGENT AI로 CPU 수요가 다시 커지는 구간에서, AMD는 서버 CPU 점유율을 늘리고 있고 EPYC 제품군이 계속 인텔 점유율을 가져오고 있다
-
ARM : Arm 자체와 Arm 기반 서버 CPU를 쓰는 하이퍼스케일러들이 수혜를 받을 가능성이 크다. Arm CPU는 전력 효율이 좋고, AI 서버에서는 호스트 CPU 또는 트래픽 컨트롤러 역할이 커지고 있어서 구조적 점유율 확대가 예상된다.
-
NVDA (베라루빈)
-
INTC
6. 베라 루빈의 등장
베라루빈(Vera Rubin) 은 엔비디아의 차세대 AI 플랫폼으로, 단순히 빠른 칩이 아니라 AI 팩토리 전체를 처음부터 다시 설계한 시스템이다.
-
3.3 배 성능 향상: 블랙웰 (Blackwell) 대비 3.3 배 성능, 3.5 배 학습, 5 배 추론 향상
-
HBM4 탑재: 6 세대 고대역폭 메모리 (SK 하이닉스·삼성전자 독점 공급), 8 개 HBM4 스택으로 초고대역폭
-
Vera CPU 통합: 기존 Grace CPU 를 잇는 철저히 AI 전용 설계 CPU, AI 에이전트의 도구 호출·코드 실행·데이터 처리 담당
-
랙 스케일 아키텍처: NVL72(72 개 CPU + 144 개 GPU) → 하나의 슈퍼컴퓨터
-
전력 효율: 블랙웰 대비 토큰당 연산 비용 크게 낮음
베라루빈이 가져올 CPU 시장 경쟁
베라루빈은 엔비디아의 CPU 영역 직접 진출을 의미하며, x86(Amd·인텔) vs Arm 경쟁에 엔비디아가 추가되는 구조적 변화를 만든다
경쟁 구도
-
엔비디아 vs AMD vs 인텔: 베라 CPU 는 AI 에이전트·강화학습·데이터 처리 전용으로 설계, 기존 x86 대비 50% 빠른 속도와 2 배 효율성
-
AMD 점유율 확대: 2026 년 1 분기 x86 서버 CPU 점유율 33.2%로 상승, 인텔 55% → 하락
-
Arm 급성장: Arm 서버 CPU 는 2025 년 50% 달성, 2029 년 90% 예상
베라루빈은 GPU 중심 AI 인프라에서 CPU+GPU 코디자인으로 전환을 알리는 신호다.
엔비디아가 CPU 영역까지 직접 진출하면서 x86 vs Arm vs 엔비디아 3파전이 시작된다
💡 관련 기업
-
SK 하이닉스, 삼성전자, 마이크론 : HBM4 공급
-
CLS : ODM 제조, AI 서버 랙·네트워크 스위치 제조, 1 위
-
FLEX : 전력관리, 냉각, 110kW 전력셸프, 액체 냉각 CDU 공급
-
한미반도체 : HBM 패키징 장비
-
HPSP : 서버 제조, 베라루빈 NVL72 지원 서버 공급
-
이오테크닉스 : HBM4 테스트 장비
-
CRWV, NBIS : 네오클라우드 기업 코어위브, 네비우스에 베라루빈 탑재 예정 (GTC 2026)
7. AI 가 클라우드 밖으로 나가고 있다
AGENT AI는 단순 답변형 AI가 아니라 실시간으로 판단하고 실행해야 한다. 그래서 클라우드만으로는 한계가 뚜렷해졌다. 핵심 이유는 지연, 보안, 비용이다.
클라우드에 매번 데이터를 보내면 응답이 늦어지고, 민감한 정보가 외부로 나가며, 요청이 많아질수록 사용료도 커진다. 그래서 AI는 점점 데이터가 있는 곳, 기기가 있는 곳, 현장이 있는 곳으로 이동하고 있다.
온프레미스 AI
온프레미스 AI는 기업이 자체 서버나 내부 데이터센터 안에서 AI를 직접 돌리는 방식이다. 금융, 의료, 공공처럼 데이터 유출이 치명적인 곳에서 특히 중요하다.
핵심은 보안과 데이터 주권이다. 데이터를 외부 클라우드로 보내지 않으니 규제 대응이 쉽고, 내부 문서·고객정보·설비 데이터 같은 민감한 데이터를 더 안전하게 다룰 수 있다.
💡관련 기업
-
CLS, FLEX: DELL·HPE 뒤에서 실제 서버, 전력, 네트워크 장비를 만드는 제조 파트너다.
-
비아이매트릭스, 코난테크놀로지, 사이냅소프트: 국내 온프레미스형 AI 소프트웨어·LLM 수요의 수혜가 기대되는 기업들이다.
온디바이스 AI
온디바이스 AI는 스마트폰, PC, 노트북, 자동차 같은 기기 안에서 직접 AI를 실행하는 방식이다. 클라우드를 거치지 않기 때문에 빠르고, 오프라인에서도 돌아가며, 개인정보 보호에 유리하다.
이 방식이 중요해진 이유는 AGENT AI가 사용자 바로 옆에서 즉시 반응해야 하기 때문이다. AI PC, AI 스마트폰, 웨어러블처럼 개인 단말이 AI의 첫 실행 공간이 되면서 온디바이스 AI가 빠르게 커지고 있다
핵심 수혜주
-
퀄컴: 저전력 AI 연산용 칩과 NPU 생태계의 핵심 기업이다
-
오픈엣지테크놀로지, 칩스앤미디어, 제주반도체: 온디바이스 AI용 IP, 영상 처리, 저전력 메모리 관련 수혜주로 자주 묶인다.
엣지 AI
엣지 AI는 공장, 카메라, 로봇, 차량, 의료기기처럼 데이터가 생성되는 현장에서 바로 AI를 돌리는 방식이다. 핵심은 클라우드로 보내기 전에 현장에서 즉시 판단한다는 점이다.
엣지 AI가 중요한 이유는 실시간성 때문이다. 자율주행, 산업 자동화, 스마트 카메라, 로봇은 몇 초가 아니라 밀리초 단위 반응이 필요해서 클라우드 왕복을 기다릴 수 없다
이 글과 같은 주제






핵심 수혜주
-
엔비디아: 엣지 AI용 GPU·플랫폼 생태계의 중심 기업이다.
-
퀄컴, 미디어텍: 저전력 엣지 AI 칩 수요의 핵심 수혜주다
-
삼성전자, SK하이닉스, 마이크론: 엣지 AI 확산으로 메모리 수요가 커지는 대표 수혜주다.
-
LSCC, CEVA, SYNA: 저전력 FPGA, 설계 IP, 연결 인터페이스 측면에서 엣지 AI 수혜주로 볼 수 있다.
8. 전력반도체의 중요성
왜 중요해졌나
AI 서버는 이제 연산보다 전기를 어떻게 안정적으로 넣고, 덜 잃고, 열을 덜 내게 바꿀 것인가가 더 중요해졌다. 엔비디아도 기존 54V 랙 전력 구조로는 앞으로의 MW급 AI 랙을 감당하기 어렵다고 보고, 2027년부터 800V HVDC 기반 데이터센터 전력 인프라 전환을 추진하고 있다.
핵심은 전력 밀도다. AI 데이터센터는 GPU가 늘어날수록 전력 손실, 발열, 냉각 부담이 동시에 커지는데, 이때 전기를 변환하고 제어하는 전력반도체가 병목이 된다. 그래서 Si 기반 부품보다 고전압·고주파·고효율에 강한 GaN, SiC 전력반도체가 핵심 부품으로 올라왔다.
왜 SiC와 GaN인가
SiC는 고전압, 고온, 고열 환경에 강해서 대전력 변환에 유리하다.
실제로 SiC는 높은 항복전압, 높은 열전도도, 높은 동작 주파수, 높은 동작 온도 특성 때문에 전력 손실을 줄이고 열 관리와 시스템 소형화에 유리하다고 평가된다
GaN은 더 높은 스위칭 주파수와 높은 전력 밀도에 강하다. AI 데이터센터용 800V 아키텍처에서는 GaN이 SiC보다 더 높은 주파수를 지원해 고밀도 전원 공급 구조에 적합하다는 설명이 나온다.
800V HVDC가 만든 변화
800V HVDC 전환의 의미는 단순한 전압 상승이 아니다. 전력 효율 개선, 유지보수 비용 절감, 전력 밀도 확대를 동시에 노리는 구조 변화다.
엔비디아와 나비타스가 제시한 800V HVDC 구조는 기존 54V 시스템 대비 전력 효율 최대 5%포인트 개선, 유지보수 비용 70% 절감 효과를 제시했다.
이 구조 변화는 전력반도체를 “보조 부품”에서 “AI 인프라 핵심 부품”으로 올려놨다.
GaN 전력반도체 시장은 2023년 2억7,100만 달러에서 2030년 43억7,600만 달러로 연평균 49% 성장할 전망이라는 분석도 나왔다
밸류체인
전력반도체 밸류체인은 간단히 보면 전력 공급 → 전압 변환 → 랙 분배 → 서버 내부 전원 변환 구조다. 여기서 전력반도체는 UPS, PSU, DC-DC 컨버터, 전력 모듈 안에 들어가며, AI 서버가 고전력화될수록 중요도가 커진다.
-
소자 소재/칩: GaN, SiC 전력반도체
-
전력 모듈/변환: PSU, 정류기, DC-DC 컨버터power+1
-
전력 장비: HVDC 전력 공급 장치, 분전 시스템, 랙 전력 인프라
-
최종 수요처: AI 데이터센터, AI 서버, MW급 랙
AI 시대에 전력반도체가 중요해진 이유는 간단하다. GPU를 더 많이 꽂는 것보다, 그 전기를 효율적으로 바꾸고 버티게 하는 것이 더 중요해졌기 때문이다.
엔비디아가 2027년부터 800V HVDC 기반 AI 데이터센터 전력 구조로 전환하겠다고 밝히면서, 고전압·고효율에 강한 GaN·SiC 전력반도체가 핵심 부품으로 부상했다.
가장 직접적인 수혜주는 나비타스, 글로벌 밸류체인에서는 인피니언·ST·TI·ROHM, 국내에서는 LS일렉트릭·HD현대일렉트릭·효성중공업·산일전기 같은 전력 인프라 기업들이 핵심 수혜 축으로 볼 수 있다.
💡관련 기업
-
TXN : NVIDIA 공식 협력사
-
ON : NVDIA 공식 협력사, SiC 수직통합 유일
-
NVTS : 순수 GaN 유일
-
STM : 유럽 최대 SiC + GaN
-
MPWR : DC-DC/IC
-
COHU : 테스트 장비
-
AMKR /ASE: 패키징
-
DB하이텍 : 국내 최대 8인치 파운드리
-
KEC : SiC 1200V 국산화
-
RFHIC : 국내 유일 GaN 대량생산
-
RF머트리얼즈 : GaN RF 패키지, 에피웨이퍼 국산화
-
큐알티 : 전력반도체 신뢰성 평가 전문, HBM 테스트
-
에이엘티 : 비메모리 후공정 토탈 솔루션
9. 서버의 병목 — 브랜드 서버 기업 vs ODM/EMS
AGENT AI 시대로 오면서 병목은 서버 전체 시스템으로 옮겨갔다.
클라우드 밖으로 AI가 이동하면, 데이터센터 하나만 쓰던 게 아니라 여러 곳에서 각각 서버를 따로 구축해야 한다
클라우드 한 곳에서 수천·수만·수십만 곳으로 설치지가 분산되면서, 서버 전체 수요가 기하급수적으로 늘었다.
지금은 GPU 한 개를 확보하는 것보다, 그 GPU가 제대로 돌아가게 만드는 메모리, 전력, 냉각, 기판, 네트워크가 모두 맞물린 서버를 제때 공급하는 것이 더 어려워졌다.
특히 AI 서버는 기존 범용 서버보다 전력 밀도가 훨씬 높고, 전력 공급 체계도 더 복잡하다. 차세대 GPU 전력 소모가 치솟으면서 전력 변환과 제어 부품 탑재량이 구조적으로 늘어났고, 그 결과 서버 조립과 납품 자체가 병목이 되기 시작했다. 시장에서는 기판, 전력반도체, 냉각 같은 부품 병목이 서버 성장률까지 낮출 수 있다고 보고 있다.
브랜드 서버 기업은 무엇을 하나
브랜드 서버 기업은 쉽게 말해 서버를 설계하고, 통합하고, 고객에게 파는 회사다. 대표적으로 DELL, HPE 같은 기업이 여기에 해당한다.
이들은 GPU, CPU, 메모리, 스토리지, 전력장치, 냉각장치, 네트워크를 하나의 시스템으로 묶어 최종 고객에게 공급한다. 즉, 고객이 보는 “완성품 서버”의 얼굴이 브랜드 서버 기업이다.
ODM / EMS 는 무엇인가
ODM은 Original Design Manufacturer의 약자로, 제조사가 설계와 생산을 함께 맡는 모델이다. 고객사 요구에 맞춰 제품을 개발하고 제조한 뒤, 브랜드 기업이 그 제품을 판매하는 구조다.
EMS는 Electronics Manufacturing Services의 약자로, 제조, 조달, 일부 설계, 테스트, 물류까지 포함한 전자 제조 서비스 모델이다. 쉽게 말하면 단순 조립 공장이 아니라, 브랜드 기업 대신 공급망과 생산을 운영해주는 제조 파트너다.
핵심 차이는 이렇다. 브랜드 서버 기업은 시장과 고객을 잡고, ODM/EMS는 실제 제품을 설계·생산·조달·물류로 뒷받침한다.
AI 서버 시장에서는 이 둘이 경쟁자라기보다 공생 구조다. 브랜드 서버 기업이 고객을 확보하고 서버 사양을 정하면, ODM/EMS가 이를 실제 제품으로 빠르게 구현한다.
예를 들어 DELL·HPE 같은 브랜드 기업은 기업 고객과 하이퍼스케일러에 AI 서버를 판매하지만, 그 안에 들어가는 섀시, 보드, 랙, 전력 시스템, 일부 네트워크 장비는 Celestica, Flex 같은 ODM/EMS 파트너가 설계·조달·생산하는 식이다. 그래서 AI 서버 주문이 폭증할수록 브랜드 기업만이 아니라 ODM/EMS 기업도 같이 주목받는다.
왜 ODM/EMS가 더 중요해졌나
AGENT AI 시대에는 서버가 단순 조립품이 아니라 고밀도 전력·고속 네트워크·액체 냉각·고급 기판이 동시에 들어가는 복합 시스템이 됐다. 이런 구조에서는 브랜드 기업 혼자서 모든 제조를 감당하기 어렵고, 공급망을 빠르게 돌릴 수 있는 ODM/EMS의 가치가 커진다.
특히 Celestica는 전통적인 EMS에서 고부가가치 ODM 모델로 전환하는 것이 성장 포인트로 평가되고 있고, Flex 역시 제조를 넘어 조달·물류·전력 솔루션까지 맡는 구조로 확장하고 있다.
💡관련 기업
- HPE, DELL, SMIC, PENG, CLS, FLEX
10. AI PC 시장 확대
AI PC 시장이 커지는 가장 큰 이유는, AI가 이제 단순히 답만 하는 도구가 아니라 사용자 옆에서 바로 실행하는 개인용 에이전트로 바뀌고 있기 때문이다.
AGENT AI는 문서 요약만 하는 게 아니라 일정 정리, 파일 검색, 회의 정리, 앱 실행, 작업 추천처럼 즉시 반응하고 계속 보조해야 해서, 클라우드 왕복만으로는 한계가 있다
그래서 AI가 클라우드에서 PC 안으로 들어오기 시작했다. 온디바이스에서 바로 실행하면 지연이 줄고, 개인정보가 밖으로 덜 나가고, 인터넷이 없어도 일부 기능이 돌아간다. 즉, AI PC는 AGENT AI 시대의 개인용 실행 플랫폼이다.
AI PC는 쉽게 말해 CPU, GPU 말고 NPU까지 넣어서 AI를 기기 안에서 직접 돌릴 수 있는 PC다. 핵심은 생성형 AI 기능을 클라우드 의존 없이 일부 로컬에서 처리할 수 있다는 점이다.
이런 구조 덕분에 AI PC는 회의 요약, 실시간 번역, 문서 정리, 이미지 생성 보조, 개인화 추천 같은 기능을 더 빠르고 자연스럽게 수행한다. Microsoft의 Copilot+ PC가 이 시장의 대표적인 기준점이 됐다.
점유율
AI PC는 이제 틈새가 아니라 주류로 넘어가는 단계다. 가트너 기준으로 AI PC 비중은 2024년 15.6%, 2025년 31.0%, 2026년 54.7%로 전망됐고, 2026년 출하량은 1억 4,311만 대 수준으로 제시됐다.
시장에서는 2026년에 AI PC가 전체 PC 판매의 절반을 넘는다는 전망이 공통적으로 나온다. ASUS도 2026년 AI PC가 전체 판매의 50%를 넘고, 2027년에는 60% 이상 갈 수 있다고 봤다.
엔비디아·마이크로소프트·Arm 신형 AI PC
가장 중요한 변화는 엔비디아가 소비자 PC 시장에 본격 진입했다는 점이다. 엔비디아는 Microsoft와 함께 개인용 AI 에이전트 시대를 위한 Windows PC를 내세우며, RTX Spark라는 새 슈퍼칩을 공개했다.
이 흐름의 핵심은 Arm 기반 Windows AI PC다. Microsoft는 Copilot+ PC를 통해 AI PC 기준을 먼저 만들었고, 그 초기 축은 Windows on Arm이었다. 여기에 엔비디아도 Arm 기반 PC 프로세서 출시 가능성이 강하게 제기되면서, 마이크로소프트 + 엔비디아 + Arm 조합이 신형 AI PC의 새 축으로 떠올랐다.
💡관련 기업
- ARM , NVDA, MSFT, DELL, ARM, QCOM
11. 네오클라우드의 중요성
네오클라우드란
네오클라우드는 쉽게 말해 AI 전용 GPU 클라우드다. AWS나 Azure처럼 범용 서비스를 다 하는 구조보다, GPU 컴퓨팅과 AI 워크로드에 집중해서 더 빠르게 공급하는 모델이다.
이들은 하이퍼스케일러를 대체하기보다, 부족한 GPU 용량을 메우는 보완자에 가깝다. 그래서 AI 붐이 강할수록 네오클라우드가 더 중요해진다.
왜 네오클라우드로 가는가
클라우드의 점유율이 하이퍼스케일러에서 네오클라우드로 이동하고있다.
클라우드에서 네오클라우드로 이동하는 이유는 기존 클라우드가 AI를 제대로 못 따라가기 시작했기 때문이다.
핵심은 GPU 가용성, 대기 시간, 비용, 전문성 4 가지다.
1) GPU 가용성: 기존 클라우드는 GPU가 부족하다
생성형 AI 급증으로 GPU 수요가 폭증했지만, 기존 하이퍼스케일러에서는 GPU 확보에 2~4 주, 심한 경우 3 개월 이상 기다려야 했다.
AI 기업 약 3 분의 1이 GPU 확보 지연 문제를 겪고 있고, 어떤 기업은 90 일을 기다려야 한다. AGENT AI는 추론 호출이 많고 실시간성이 중요해서 이런 대기 시간은 프로젝트 자체가 지연되는 수준이다.
2) 대기 시간: 기존 클라우드는 너무 느리다
기업 AI 사용자의 약 3 분의 1이 대기 시간 단축이 네오클라우드를 선택한 가장 큰 이유라고 답했다.
기존 클라우드는 범용 워크로드 (웹 서비스, 데이터베이스, 스트리밍 등) 를 처리하도록 설계되어, AI 연산 전용으로 쓰면 비효율과 지연이 발생한다. 반면 네오클라우드는 GPU 중심 아키텍처, 고속 네트워크(NVLink, InfiniBand) 등 AI 연산에 최적화된 인프라를 제공한다.
3) 비용: 기존 클라우드는 비싸다
네오클라우드 사용의 주요 이유로 비용을 꼽은 비율은 13% 였지만, 그중 반절 가까이가 기존 클라우드 대기업에서 네오클라우드로 전환하며 25% 이상 비용 절감했다고 응답했다.
기존 하이퍼스케일러의 GPU 인스턴스는 범용 인프라 위에 얹힌 구조라 AI 연산 전용으로 쓰면 돈이 줄줄 샌다는 비판이 많았다. 실제로 NVIDIA H100 DGX 인스턴스 기준 네오클라우드의 시간당 요금이 하이퍼스케일러 대비 약 66% 저렴하다는 분석도 나왔다.
또한 네오클라우드는 데이터 송신이나 저장소와 관련해 숨은 비용이 적어 전체 비용을 예측하기 훨씬 수월하다.
4) 전문성: 기존 클라우드는 범용, 네오클라우드는 AI 전용
네오클라우드는 불필요한 요소를 덜어낸 구조다. 소수의 일을 매우 잘하도록 설계되어, GPU 용량을 빠르게 제공하고 AI 워크로드에 최적화된다.
기존 클라우드는 범용 워크로드를 처리하도록 설계된 반면, 네오클라우드는 GPU 중심 아키텍처, AI 소프트웨어 스택을 기본적으로 탑재한다. 이는 고도화된 GPU 기반 AI 워크로드에서 일반 클라우드보다 더욱 경쟁력이 있다.
💡관련 기업
CRWV
CoreWeave는 현재 네오클라우드의 대표주자다. 시장에서는 CoreWeave를 가장 큰 네오클라우드 사업자로 보고 있으며, 장기 계약과 대규모 백로그를 바탕으로 빠르게 성장 중이라고 평가한다.
강점은 GPU 클라우드 플랫폼 자체다. 단순 데이터센터 임대가 아니라, AI 워크로드를 위한 관리형 GPU 서비스와 소프트웨어 레이어까지 함께 제공하는 풀스택 구조가 핵심이다.
NBIS — Nebius
Nebius는 네오클라우드 중에서도 가장 공격적인 확장 기업 중 하나다. AI 개발자용 GPU 클러스터와 클라우드 플랫폼을 제공하며, 2026년 말 연간 매출 런레이트를 70억~90억 달러까지 키우겠다는 목표를 제시했다.
또한 Microsoft와 Meta 같은 대형 고객과 계약을 맺으며 하이퍼스케일러 검증도 받았다. 여기에 엔비디아 투자까지 더해지면서 시장 주목도가 높아졌다.
IREN
IREN은 원래 비트코인 채굴 인프라 기반에서 출발했지만, 지금은 AI 클라우드·HPC 인프라 기업으로 전환 중이다. 핵심은 전력과 부지를 이미 확보한 상태에서 AI용 GPU 인프라로 빠르게 바꾸고 있다는 점이다.seekingalpha+1
특히 Microsoft와의 5년 계약이 시장의 시선을 끌었다. 시장에서는 IREN을 “전력 기반 인프라를 AI 클라우드로 바꾸는 대표 사례”로 본다.
APLD — Applied Digital
Applied Digital은 다른 네오클라우드와 조금 다르다. 직접 클라우드 플랫폼을 운영하는 것보다, 액체냉각 기반 AI 데이터센터 캠퍼스와 임대 인프라에 강점이 있다.
즉, APLD는 “GPU를 서비스로 파는 회사”라기보다 AI용 데이터센터를 짓고 임대하는 인프라 사업자에 가깝다. AGENT AI가 커질수록 GPU뿐 아니라 전력·냉각·캠퍼스 자체가 부족해지기 때문에 이런 유형도 중요해진다.
12. AI 기판 병목
AGENT AI 에서 기판이 병목으로 등장한 배경은, AI 가 GPU 성능만 높이는 게 아니라 “연속적인 대규모 추론”을 실시간으로 처리하면서 기판의 기술 난도와 공급 압력이 동시에 급상승했기 때문이다.
| 원인 | 설명 |
|---|---|
| 연산 성능 향상 → 신호 처리량 급증 | AI 반도체 연산 성능이 높아질수록 더 많은 신호를 더 빠르게 처리해야 하므로 기판 기술 난도가 급격히 상승 |
| 미세공정 경쟁 → 패키징 경쟁 확장 | 반도체 미세공정 경쟁이 패키징 경쟁으로 확장되면서, 기존 CoWoS 병목이 FC-BGA·ABF·고다층 MLB 쪽으로 전이 |
| 실시간 대규모 추론 → 기판·부품 수요 비선형 | AGENT AI 는 반복 호출·대화 지속·멀티스텝 계획이 많아서 GPU·MLCC·PCB·기판 수요가 단순 비례가 아니라 배수로 증가 |
| HBM 기판과 생산라인 충돌 | HBM 기판과 소형 PCB(mSAP) 생산라인이 충돌하면서 납기가 6 주→6 개월로 늘어, 공급망 병목이 전방위로 확산 |
| 공급사 교체 시 인증 6 개월+ | 기판·부품 공급사 교체 시 인증 기간이 6 개월 이상 필요해서, 병목이 구조적으로 지속될 가능성이 높음 |
| 패키징·언더필·테스트·광통신·프로브카드 증설 속도 느림 | 핵심 부품 공급업체들의 증설 속도가 더 느려 병목이 전방위로 확산, 병목 구간이 가격 결정권 영역으로 부상 |
| 브로드컴의 AI 공급망 제약 지목 | 브로드컴이 TSMC 첨단 공정, 레이저, 광트랜시버용 PCB를 핵심 제약으로 지목, 광트랜시버 PCB 리드타임 6 주→6 개월 |
AI 서버는 칩 성능만 높아진 것이 아니라 패키지 크기, 배선 밀도, 전력 소모, 네트워크 속도가 동시에 올라가면서 기판과 부품의 사양도 급격히 높아졌다. 그 결과 병목은 순서대로 CoWoS 패키징 → ABF/FC-BGA → MLB/CCL → MLCC로 전이되는 모습이며, 특히 고다층·대면적·저손실 소재 대응이 가능한 업체에 수혜가 집중된다.
FC-BGA / ABF / 유리기판
-
FC-BGA : 고밀도 패키지기판, 반도체 칩을 위로 뒤집어(Flip-Chip) 실장하는 고성능 기판, GPU, CPU, AI 칩을 기판에 연결, 고전력·고신호 처리 담당
-
ABF 기판 : FC-BGA의 핵심 절연재, FC-BGA 기판에서 절연층을 만드는 필름 소재, FC-BGA 기판의 고다층 구조를 가능하게 하는 핵심 재료, ABF 없이 고성능 FC-BGA 제작 불가
-
유리기판 : 기존 유기기판(ABF)의 휘어짐·열·정밀도 한계를 해결
FC-BGA 병목의 핵심 배경은 AI GPU와 ASIC이 커질수록 기판 층수와 면적이 동시에 증가하는데, 하이엔드 제품은 증설 속도가 수요를 따라가지 못하기 때문이다. 미래에셋증권은 Hopper에서 Blackwell, Rubin, Feynman으로 갈수록 FC-BGA 소요량과 ABF 층수가 계속 올라가고, 2026년 이후 서버용 FC-BGA는 공급자 우위로 전환될 가능성이 높다고 분석했다.
FC-BGA : AI GPU/ASIC 대면적화, 층수 증가, 증설 속도 제한
ABF 기판 : CoWoS 완화 이후 병목 전이, 고다층 ABF 수요 급증
💡 관련 기업
-
삼성전기 : FC-BGA와 MLCC를 동시에 보유한 대표 수혜주
-
대덕전자 : 서버·반도체용 FC-BGA
-
LG 이노텍 : CPU향 FC-BGA 진입으로 ASP 개선 기대
미국 상장사 중에서는 순수 ABF 생산업체보다 패키징·조립·고신뢰 기판 쪽이 더 현실적
-
AMKR : 첨단 패키징 확장 수혜
-
SANM (Sanmina) : AI 서버 인프라용 백플레인·기판 조립 수혜
-
유리기판 : SKC, 삼성전기, 켐트로닉스 / INTEL , GLW
PCB·MLB·CCL
-
PCB : 인쇄회로기판, 전자기기에서 여러 부품을 연결하는 기본 기판
-
MLB : 다층회로기판, PCB 를 여러 층(보통 4 층 이상) 으로 쌓은 기판, AI 서버는 18 층 이상 고다층 MLB 가 필수
-
CCL : 동박 적층판, PCB 를 만드는 기초 재료, 신호 손실과 전압 안정성 결정, AI 서버는 M8→M9 계열 저손실 고성능 CCL 필요, 저 CTE 유리섬유 + HVLP 동박 공급 제약으로 병목 발생
PCB와 MLB 병목은 AI 서버·스위치·네트워크 장비가 초고속화되면서 18층 이상 고다층 MLB 수요가 빠르게 늘고, 공정 부하와 수율 난도가 같이 상승하기 때문에 발생. 특히 미래에셋증권은 18층 이상 MLB가 2024~2029년 가장 높은 성장률을 보일 세그먼트라고 봤고, 다중 적층 공법 확대가 ASP 상승의 핵심이라고 설명
CCL 병목은 PCB의 상위 소재 병목. AI 서버와 800G·1.6T 네트워크 확대로 저유전·저손실 특성을 가진 하이엔드 CCL(M8·M9 계열) 수요가 구조적으로 증가했고, 여기에 저 CTE 유리섬유와 HVLP 동박 같은 원재료 공급 제약까지 겹치면서 병목이 생겼다. 즉, PCB가 더 고속화될수록 단순 적층판이 아니라 “고성능 CCL을 소화할 수 있는 공급망”이 부족해지는 구조
💡관련 기업
-
PCB 기판 : 심텍 , 티엘비 , 코리아써키트 , TTMI
-
MLB 기판 : 이수페타시스, 대덕전자
-
CCL : 두산, 솔루스첨단소재, 롯데에너지머트리얼즈
**미국내 생산하는 PCB 기판 기업은 TTMI (TTM Technologies) 가 유일하다
MLCC
- MLCC : 세라믹을 여러 층으로 쌓은 초소형 커패시터(전하 저장 부품), 전력 안정화 + 신호 필터링 + 전압 급변동 방지
MLCC 병목은 AI 서버의 전력 소모 증가와 직접 연결됨. GPU와 ASIC의 전력 소모가 커질수록 고신뢰성·초고용량 MLCC 탑재량이 비선형적으로 증가하고, 선두 업체들의 가동률이 90~100%에 근접하는데도 Capex는 보수적으로 유지돼 공급이 빠르게 늘지 못하는 구조. 따라서 MLCC는 단순 보조부품이 아니라 전력 안정화 병목으로 봐야 한다.
💡관련기업
-
삼성전기 : PCB(FC-BGA) + MLCC 겹호재 대형주, 엔비디아 차세대 랙에서 PCB +233%, MLCC +182% 동시 폭증
-
LG이노텍 : PCB + MLCC 동시 생산, 겹호재
차세대 패키징 기술
-
미세공정 한계 → 패키징으로 성능 확장
-
반도체 미세공정 (3nm, 2nm) 이 한계로 다가오면서, 패키징으로 성능과 전력 효율을 확장하는 방식이 핵심 전략으로 부상
-
TSMC 의 CoWoS(Chip on Wafer on Substrate) 같은 패키징 기술이 AI 반도체의 핵심 경쟁력으로 자리 잡음
-
-
AI 칩 대면적화 → 단일 웨이퍼 칩 수 감소
-
Hopper 30 개 → Blackwell 16 개 → Rubin 6 개로 12 인치 웨이퍼 1 장당 순수 칩 수가 급감
-
대면적 칩을 효율적으로 패키징하기 위해 CoWoS, FO-PLP(Fan-Out Panel Level Packaging) 같은 차세대 기술이 필수
-
-
HBM 연동 → 패키징 복잡도 증가
-
고대역폭 메모리 (HBM) 를 AI 칩과 한 패키지에 통합해야 하므로, 패키징 단계가 공급망 병목으로 작용
-
TSMC CoWoS CAPA 가 수요를 따라가지 못해 2024~2025 년까지 패키징 병목이 심화
-
-
다중 칩 통합 → 인터포저·리덱터 필요
-
GPU, CPU, 메모리, 네트워크 칩을 하나의 패키징 구조로 묶어야 하므로, 실리콘 인터포저, 리덱터, 언더필 같은 부재와 공정이 필수
-
기존 FC-BGA 와 실리콘 인터포저가 동시에 한계를 드러내면서, 유리기판(Glass Substrate) 같은 차세대 대안이 등장
-
-
패키징 병목 → 기판 병목 전이
-
2026 년부터 TSMC CoWoS CAPA 공격적 증설로 패키징 병목은 완화
-
하지만 병목이 ABF·FC-BGA·고다층 MLB·고성능 CCL·MLCC로 전이
-
AI 반도체 경쟁의 핵심은 이제 칩 자체보다 패키징과 기판에 있다.
-
CoWoS 병목 완화 → FC-BGA·ABF·고다층 MLB·고성능 CML·MLCC 병목 등장
-
차세대 패키징 기술 (CoWoS, FO-PLP, 유리기판) 이 대면적 칩·HBM 연동의 핵심
3DIC 최근 뉴스: AI 반도체의 새 병목, 첨단 패키징 (2026)
3DIC은 칩을 위아래로 쌓아 한 패키지로 묶는 기술이다. 칩 간 거리가 짧아 데이터 주고받기가 빨라지고 전력 소모가 줄어든다. TSMC의 CoWoS, SoIC, 인텔의 Foveros, 삼성의 I-Cube가 각사의 구현 방식이다. HBM도 DRAM 다이를 쌓는 3DIC 방식이다.
시장 규모가 급팽창한다. Mordor Intelligence는 2.5D·3DIC 시장이 2025년 112억 4,000만 달러에서 2026년 148억 4,000만 달러로 커졌고, 2031년까지 연평균 32% 성장해 451억 9,000만 달러에 이를 것으로 봤다. 수요는 있는데 공급이 못 따라간다. 엔비디아가 CoWoS 물량의 60%를 쓴다는 분석이 나오며 CoWoS 라인이 병목이 됐다.
TSMC는 2026년 말까지 CoWoS 생산을 월 15만 장 웨이퍼로 끌어올리겠다고 밝혔고, 설비투자 520억~560억 달러의 상당 부분을 패키징에 투입한다. 문제는 기술 한계다. 12층 HBM3E 수율은 50% 초반에 머물고, 8층에서 70~80%인 수율이 12층으로 올라가면 50% 밑으로 떨어져 패키지당 비용이 거의 두 배로 뛴다. 패키지 전력은 Blackwell·Rubin급 칩에서 1,400~2,000와트를 넘겨 기존 냉각으로 감당하기 어렵다.
설계 자동화도 아직 미완성 구간이다. Cadence는 2026년 4월 Millennium과 Allegro X AI를 내놨지만, 최종 검증(signoff)은 여전히 고객의 고통이라고 말했다. 생태계 확장 움직임은 뚜렷하다. imec 산하 IC-Link가 TSMC 3DFabric 얼라이언스에 합류했고, 인텔은 EMIB-T 로드맵을 공개했다. 삼성은 파운드리·메모리·패키징을 묶는 턴키 전략으로 TSMC 병목을 우회하려는 설계를 진행 중이다.
투자자 관점에서 핵심은 단순하다. CoWoS 병목 해소 속도가 GPU 출하량과 HBM 수요의 선행지표다. 3DIC 수율이 올라가야 고비용 구조가 풀리고 AI 서버 공급 속도가 빨라진다. 삼성의 HBM4와 패키징 턴키 수주 여부가 2026~2027년 국내 반도체 주가의 주요 변수다.
💡관련 기업
-
ASE : 세계 최대 첨단 패키징 전문 기업, TSMC 의 CoWoS 와 경쟁하는 CoWos 대안 기술 보유
-
AMKR : 첨단 패키징 확대 수혜, 북미 기반 고신뢰 패키징·조립 수혜
정리
이렇게 AGENT AI 로의 변곡점에 있어서 수 많은 병목이 발생한걸 알 수 있다.
이제는 기업들이 AI로 돈을 벌고 기업에서는 AGENT AI 가 사람을 대체한다.
구글의 유상증자, 메타의 투자 등 빅테크들은 CAPEX 투자를 과감히 늘리고 있고 이 투자는 멈출 수 없다.
여기서 광산 기업보다 곡괭이 기업을 잘 찾아 주도주로 잘 끌고가면 좋을것 같다.
현재 주도주인 광통신, 메모리 반도체를 주력으로 끌고 가되 다음 병목인 기업들이 수급이 몰리고 / 기술적으로 돌파하면 비중을 더 늘려보면 좋지 않을까 싶다.
게시글에 대한 피드백을 남겨주세요.
자주 묻는 질문
AI 에이전트 변곡점에서 GPU 공급 부족이 기업 이익에 어떤 병목을 만드는가?
GPU 공급 부족은 연산 용량을 제한해 비용을 올리고 제품 도입과 매출 확대를 둔화시킨다.
KV CACHE가 AI 에이전트에서 왜 병목이 되나?
KV CACHE는 수백만 토큰을 실시간으로 처리하면서 메모리 용량을 초과해 GPU가 대기하게 만든다.
실시간 추론 지연이 AI 에이전트 제품 채택에 미치는 영향과 줄이는 방법은?
실시간 추론 지연은 제품 채택을 늦춰 매출 기회를 줄인다. 대용량·저비용 메모리(HBF·NAND), 네트워크(광통신·CPO), 캐시 최적화로 완화한다.
HBF란 무엇이며 메모리 시장에 어떤 의미인가?
HBF는 NAND 기반 고대역폭 플래시로 HBM의 용량 한계를 8~16배 보완한다. 상용화 시 대용량 캐시 수요로 수익성 개선 요인이 된다.
NAND와 HDD 중 AI 인프라에서 어느 쪽이 더 중요한가?
용도에 따라 다르다. NAND는 대용량 저비용 KV CACHE에, HDD는 학습·추론 데이터 장기 보관용으로 중요하다.



















댓글 0
첫 댓글을 남겨보세요.